Lesson Objective
- Be familiar with a hash table and its different uses.
- Be able to apply simple hashing algorithms.
- Know what is meant by a collision and how collisions are handled using rehashing.
- Add data to and remove data from a hash table.
KS3, GCSE, A-Level Computing Resources
Imagine you have a large collection of data, like customer records in a database. You need to be able to find the information you need quickly, without having to look through every single record.
One way to do this is to create an index. An index is like a list of all the records in your database, along with the address of each record. This way, you can quickly find the record you need by looking up its address in the index.
Indexing
To create an index, you use a special algorithm called a hashing algorithm. A hashing algorithm takes a key, which is a unique identifier for a record, and turns it into an address. The address tells you where the record is stored in the database.
For example, let's say you have 300 customer records, and each record has a unique 6-digit identifier. You can create an index by dividing each identifier by 1000 and taking the remainder as the address. This will give you 1000 possible addresses, which is more than enough to store your 300 records.
Locating Data
Let's say you want to find the record for customer with identifier 123456. You would first divide 123456 by 1000, which gives you 123. The remainder is 456, so the address of the record for customer 123456 is 456.
You can now look up address 456 in the index to find the record you need. This is much faster than looking through all 300 records in the database.
Example 1: Hashing an Integer Value
In the example below the integer data value is used as a "key" within the hashing function to calculate the memory address (index) location within the hash table. A simple example of a hashing algorithm/calculation would involve carrying our a MOD operation on the key and the number of available memory/index addresses. In the examples below, the number of available addresses is 10.

Example 2: Hashing a String Value
In this example, the same hashing principle applies. However, they key is calculated by adding the ASCII values of each character in the string.
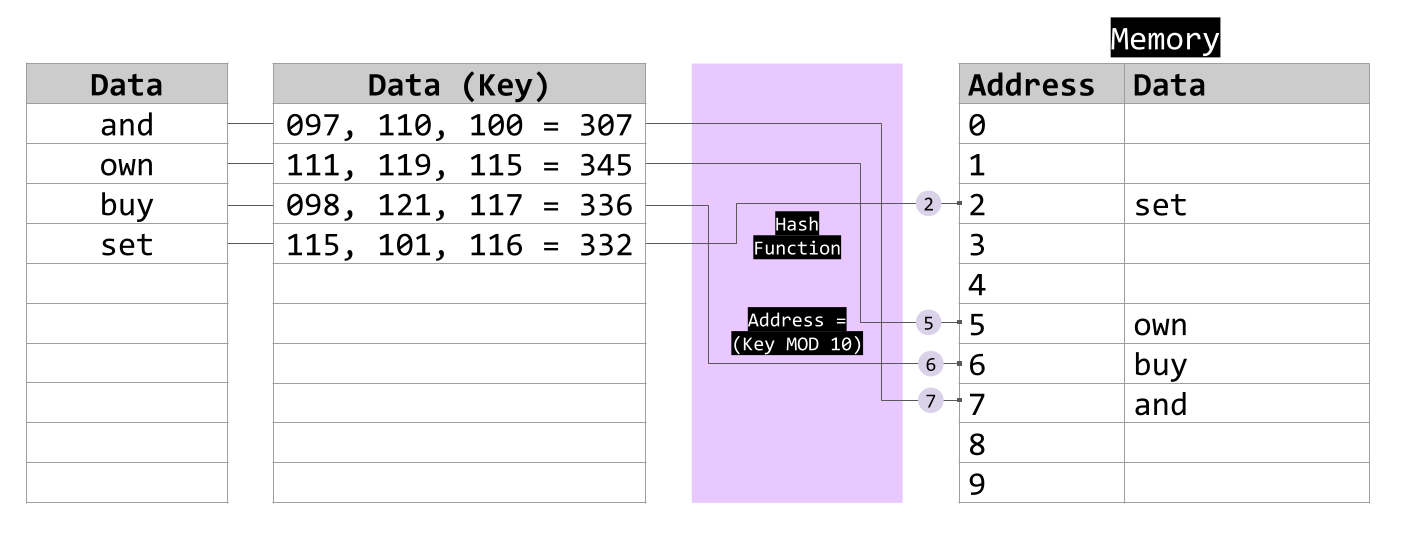
Consider the example 10 space hash table. The hash function sets "and" to location 7, "own" to 5, "buy" to 6, and "set" to 2.
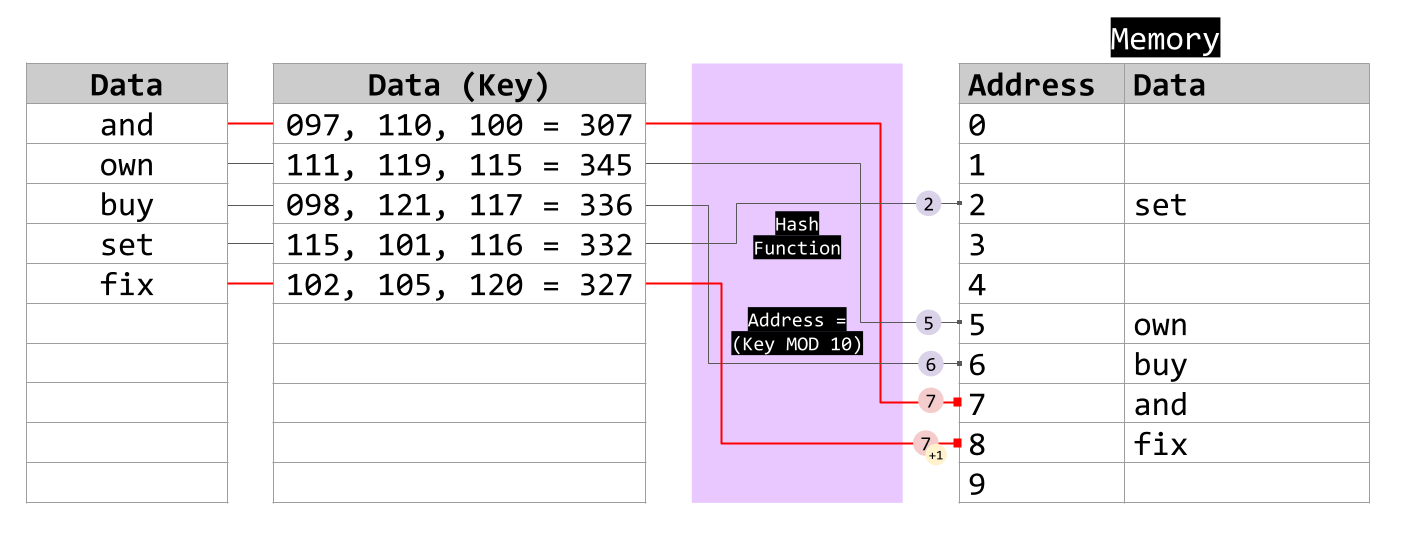
Insertion of the word "fix":
When "fix" is inserted, the hash function maps it to location 7. However, since location 7 is already occupied by "and", a collision occurs. To resolve this collision, the hash table uses the open addressing technique of linear probing.

Linear Probing:
Linear probing involves searching for the next available slot in the hash table, starting from the original index. In this case, the next available location is location 8, which is empty. So, "fix" is inserted into location 8.
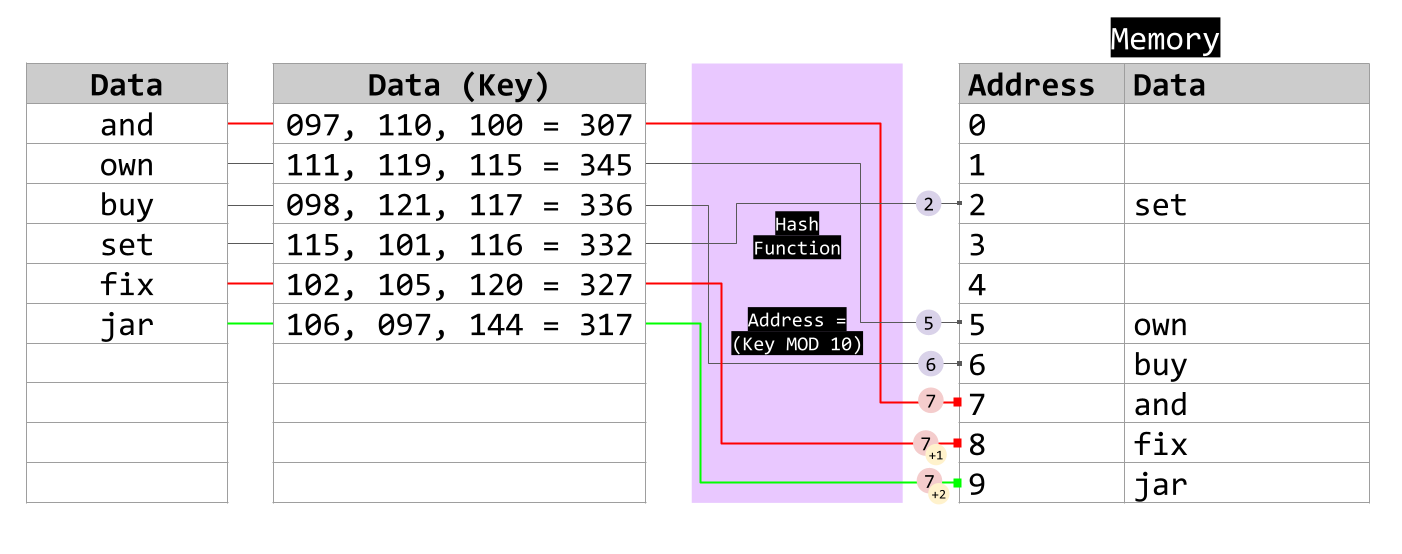
When "jar" is inserted, the hash function maps it to location 7. However, since location 7 is occupied by "and", another collision occurs. To resolve this collision, linear probing searches for the next available slot, which is location 8. However, location 8 is now occupied by "fix". We could continue the linear probe technique and go to the next memory location... Would this be the best thing to do?
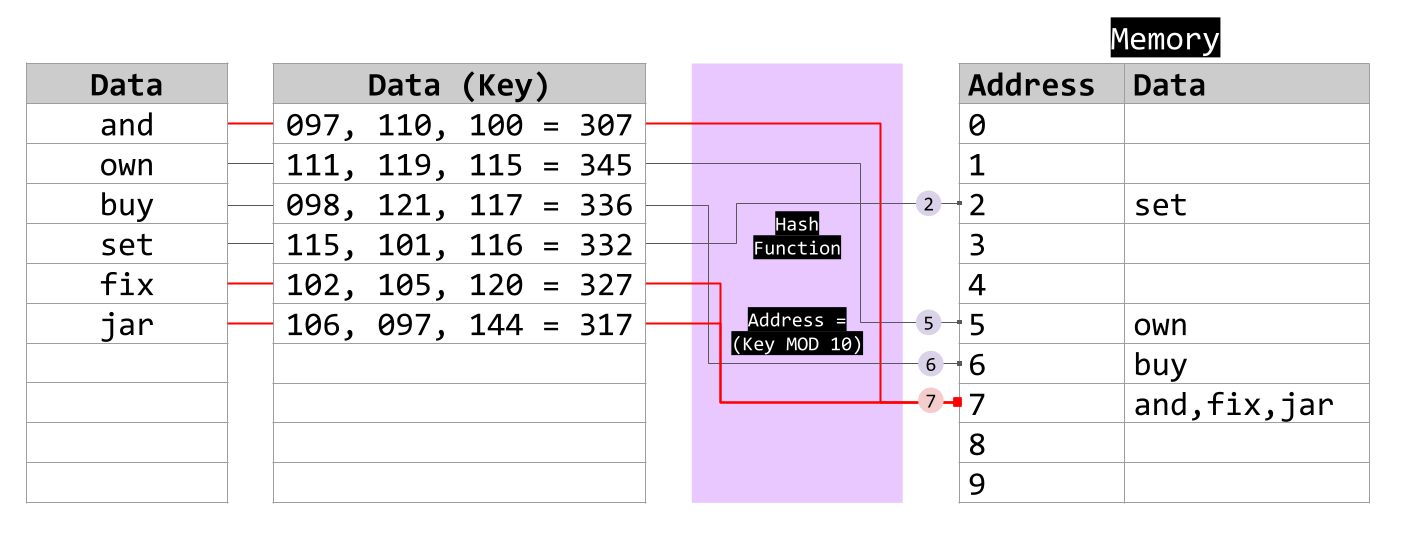
The process of finding an alternative position for an item in a hash table is known as rehashing. Here are some example techniques that could be used.
Double hashing: Involves using a second hash function to calculate an alternative index.
Chaining: Used in heavily loaded tables. This can lead to a situation where multiple items are stored in the same location. This would involve using a 2D array hash table.
Overflow tables: Having an alternate table to store any collisions.

Hash tables are used in situations where items in large data sets need to be located quickly. Hash tables are versatile data structures used in various applications due to their efficiency in storing and retrieving data. Here are some common uses:
Add:
The following steps are used to add items to a hash table:
Remove:
The following steps are used to delete items from a hash table:
Traverse:
The following steps are used to find an items in a hash table: